Machine Learning
Die In-Line Überwachung von Bauteilen oder Maschinen stellt uns häufig vor unbekannte Herausforderungen. Bei den Untersuchungen unserer Messdaten sehen wir uns immer wieder mit einem Überfluss an Informationen konfrontiert. Bei komplexen Daten mit schwer interpretierbaren Zusammenhängen gibt es die Möglichkeit, mit viel Erfahrung über das Fertigungsverfahren aus denen die Daten entstanden sind, Maschinenereignisse qualitativ mit den Daten zu korrelieren und in aufwendigen, mehrstufigen Entwicklungsschritten, diese qualitativen Merkmale mithilfe von analytischen Verfahren zu extrahieren. Dies setzt allerdings voraus, dass die Daten immer diese qualitativen Merkmale erfüllen und sich in ihrer Charakteristik nicht ändern. Andernfalls müssen die aufwendigen Entwicklungsschritte wiederholt werden, um sich einer Änderung der Daten anzupassen.
Auf Dauer ist dieser Ansatz sehr wartungsaufwendig und arbeitsintensiv. Im schlimmsten Fall bedarf es einer Langzeitbetreuung oder Neuentwicklung. Um sich den Gegebenheiten anpassen zu können und so viel Informationen aus den Daten zu extrahieren, nutzen wir gängige Verfahren des maschinellen Lernens unter Einsatz von Python und etablierten Bibliotheken wie Pytorch um unsere Daten mit den Daten des zu überwachenden Bauteils oder der Maschine zu korrelieren. Die extrahierten Features sind in der Regel robuster und werden von den entstehenden Modellen so zusammengefasst, dass sich auch Veränderungen in der Signalcharakteristik mit diesem Ansatz abbilden und bemerken lassen.
Machine Learning beim Verzahnungsschleifen und anderen komplexen Industrieanwendungen
In der Qualitätssicherung geht es darum, eine stets hohe Qualität der gefertigten Teile zu gewährleisten. Dazu existieren zwei typische Verfahren:
- Prüfung der gefertigten Teile auf bekannte Fehlerbilder
- Überwachung des Fertigungsprozesses auf Prozessveränderungen
Mit unserem Körperschall-Messsystem ist es möglich, der Maschine beim Arbeiten zuzuhören. Auf diese Weise können wir die Probleme direkt dort erkennen, wo sie entstehen und frühzeitig auf Prozessveränderungen hinweisen. Mehrere Millionen Mal pro Sekunde tasten wir das Signal ab und erhalten so ein hoch aufgelöstes Messbild des Prozesses selbst. Ein digitalisiertes Abbild dessen, was im Prozess passiert. Ganz ohne CAD-Modell erstellen wir einen digitalen Zwilling - nicht des Bauteils, sondern des Prozesses seiner Herstellung.
Ein übliches Verfahren der Qualitätssicherung ist die Überwachung eines Kennwerts auf Verletzung von Warn- und Eingriffsgrenzen. Diesem Ansatz liegt zugrunde, dass der überwachte Kennwert konstant bleibt und weitestgehend variationsfrei ist.
Die Realität sieht anders aus. Fertigungsprozesse unterliegen einer Vielzahl von Einflussfaktoren, die sich auf die Fertigung auswirken:
- Temperatur-Schwankungen
- Ausgangsmaterial
- Werkzeugverschleiß
- Vorverarbeitungsschritte
- Etc.
Je sensibler das Messgerät, desto deutlicher nimmt es natürlich auch die Auswirkungen solcher Faktoren wahr. Um jedoch höchste Qualität zu sichern, möchte man natürlich ein hochsensibles Messverfahren und möglichst enge Toleranzgrenzen nutzen. Dieser Anspruch führt dazu, dass schon kleinste Umgebungsveränderungen zu Ausschuss führen.
In der Praxis müssen also die Grenzwerte daher so angepasst werden, dass sie alle üblichen Prozessschwankungen, die noch keine Qualitätsminderung herbeiführen, umfassen.
Wir haben ein Konzept entworfen, mit dem wir trotz schwankender Produktionsbedingungen mit hoher Sensitivität messen und auswerten können. Wir setzen Machine Learning ein, um den Prozessschwankungen zu folgen.
Der übliche Ansatz wäre, dass man auf der Basis von 100.000 Messungen und der zugehörigen Beurteilung (gut/schlecht) ein Modell trainiert, um aus den Messungen automatisch die Bewertung abzuleiten.
Dieser Ansatz hat allerdings mehrere Haken: Nehmen wir mal an, wir bräuchten nur 5000 Messungen von fehlerhaften Teilen, und eine Fehlerquote von ca. 1‰, dann beläuft sich das auf 5 Mio. Teile, die bewertet und auf Fehler geprüft werden müssen. Hast du schon einmal versucht, für nur 100.000 Teile eine verlässliche und vollständige Bauteil-Fehleranalyse zu erhalten? Und bist du sicher, dass du die üblichen Prozess-Schwankungen bei der Datengenerierung abgebildet hast?
Wir nutzen Machine Learning, um den Zusammenhang zwischen Umgebungsparametern und Körperschall-Signatur zu verstehen. Genauer gesagt, wir beobachten, analysieren und lernen daraus. Somit können wir nach einer Trainingsphase vorhersagen, welches Körperschall-Messbild wir erwarten.
Das Gute daran: Für dieses Training kriegen wir unzählige Daten – mit jedem Teil, das gefertigt wird, gewinnen wir neue Erkenntnisse über Maschinen-, Umgebungsparameter und ihre Auswirkungen auf das Messergebnis.
Sobald erkannt wurde, was das erwartbare Ergebnis ist, können die Grenzen darauf abgestimmt werden. So erhält man veränderliche Toleranz-Grenzen, die sich den erwartbaren Veränderungen anpassen können. Oder anders formuliert: Wir transformieren die Messergebnisse so, dass bekannte Prozessveränderungen herausgerechnet werden und legen den Fokus auf die Abweichungen vom Erwarteten!
Im Video siehst du diese Zusammenhänge bildlich dargestellt. Hier ging es konkret um die Veränderung von Maschinenparametern, die sich stark auf das Messergebnis auswirken. Jedes einzelne Bild der sich verändernden 3D-Landschaft repräsentiert dabei die FFT-Körperschall-Signatur der Fertigung eines Bauteils. Über die Zeit sieht man also die Prozessveränderungen im Zeitraffer. Durch die prozessimmamenten Variationen, wäre die Beurteilung der Fertigungsqualität mit dem konservativen QS-Ansatz von festen Grenzwerten nicht sinnvoll möglich.
Die Prozessveränderungen sind allerdings vorhersehbar und intendiert und sollen natürlich toleriert werden. Wir nutzen maschinelles Lernen zur Kompensation der bekannten Prozessvariationen, bereinigen also die Daten bzw. die Grenzwertbetrachtung um diese bekannte Variation und erhalten ein um ein Vielfach sensibleres Messverfahren.
Diese Methodik ist natürlich weder auf Körperschall noch auf Schleifprozesse begrenzt: Machine Learning ist darauf ausgerichtet, Strukturen und Zusammenhänge in Daten zu erkennen. Komplexe Zusammenhänge zwischen Umwelt und Fertigungsprozess bzw. seiner Messung können durch Beobachtung trainiert und erlernt werden.


 Vergleich: Rohsignal vs. Signal nach neuronaler Filterung.
Vergleich: Rohsignal vs. Signal nach neuronaler Filterung. 
Machine Learning bei der Erkennung von Schleifbrand
Unsere vollautomatisierte Schleifbrandprüfung kann schadhafte Stellen im Bauteil erkennen und anzeigen. Die Schleifbrandprüfung erfolgt als spezielle Anomalie-Überwachung. Es wird nach Materialstellen gesucht, die in ihrer Härte vom sonstigen Material abweichen.
Das genutzte Verfahren basiert auf dem Barkhausenrauschen. Dabei wird das Material magnetisch angeregt und wir beobachten das dabei entstehende Barkhausenrauschen im ferromagnetischen Material. Für reproduzierbare und präzise Messergebnisse führen wir die Schleifbrandprüfung mit einem speziellen Robotik-System durch, bei dem der Sensor mit ca. 1 mm Abstand über die Materialoberfläche geführt wird.
Das Messsignal ist abhängig von verschiedenen Einflussgrößen, z. B. Frequenz, Anregungsintensität, Material-Zusammensetzung, Eigenspannungen, aber auch vom Abstand.
Mit Hilfe von mehreren Abstandssensoren zeichnen wir zu jedem Messwert den Abstand und die Sensorverkippung auf. Dabei geht es nicht nur um den vertikalen Abstand, sondern auch um Verkippungen des Sensors.
Ähnlich wie oben beim Schleifen beschrieben, erheben wir auch hier eine zusätzliche Einflussgröße der Messung. Wir trainieren neuronale Netze, mit denen wir den Zusammenhang zwischen Sensorverkippung, Bauteil-Geometrie und Abstand erlernen.
Entstehende mechanische Schwankungen im Robotersystem können somit automatisch in der Analyse mit einberechnet und ausgeglichen werden. Durch die berührungslose Messung erfolgt die Vermessung der Produkte schnell und zerstörungsfrei.
Für die Auswertung gleichen wir dann das erhaltene Messergebnis mit den erwarteten Ergebnissen ab. Dafür liefert uns das neuronale Netz den für den aktuellen Abstand üblichen Messwert, sodass wir den Abstandseinfluss von Materialanomalien differenzieren können. Das ermöglicht uns höchste Empfindlichkeit bei der Suche nach schadhaften Stellen.
Data Augmentation
Eine allgemeine Herausforderung bei der Anwendung von Machine Learning Modellen ist dessen Übertragbarkeit. Möchte man das Modell nach dem Training auf einen neuen Datensatz anwenden, der sich in gewisser Weise zu den Daten aus dem Training unterscheidet, läuft man oft in das Problem, dass das Modell mit diesen Änderungen nur schlecht zurecht kommt. Als Konsequenz ist die Qualität der Modellausgabe entsprechend niedriger. Um dem entgegenzuwirken bedient man sich häufig Techniken der Data Augmentation, d.h. die künstliche Erweiterung unserer Daten durch gezielte Manipulation. Das kann beispielsweise eine Veränderung des Energiegrundniveaus der Messung, das Verrauschen der Daten oder eine Maskierung bestimmter Zeit- oder Frequenzbereiche sein (siehe Abbildung). Dadurch wirkt man dem Auswendiglernen bestimmter Dateneigenschaften (Overfitting) entgegen und ermöglicht somit eine bessere Generalisierungsfähigkeit.
Singular Value Decomposition zum Clustern hochdimensionaler Daten
Bei der Aufzeichnung großer Datenmengen sehen wir uns immer wieder mit der Aufgabe konfrontiert, qualitative sowie quantitative Eigenschaften, wie zum Beispiel bestimmte Signalcharakteristika, aus den Daten zu extrahieren und zu gruppieren. Dazu werden in der Regel Methoden des Unsupervised Learnings, insbesondere des Clusterings, verwendet.
Die Berechnung von Clusterings für unsere Daten ist in aller Regel herausfordernd aufgrund der hohen Dimensionalität (Curse of Dimensionality). Ein Prozessausschnitt von 64 Spektren auf der Zeitachse mit 64 Frequenzbändern resultiert bereits in einem Datenpunkt mit 4096 Dimensionen. Dazu kommt, dass die uneinheitliche Länge der Aufzeichnungen dazu führt, dass viele Methoden nicht ohne weiteres anwendbar sind.
Um beide Herausforderungen zugleich anzugehen, bedienen wir uns der Berechnung einer Singular Value Decomposition (SVD). Diese betrachtet einen Prozessausschnitt als Matrix und zerlegt diese in drei Komponenten, die dann eine einheitliche Form von wesentlichen geringerer Dimensionalität (in der Anwendung häufig < 10) liefert.
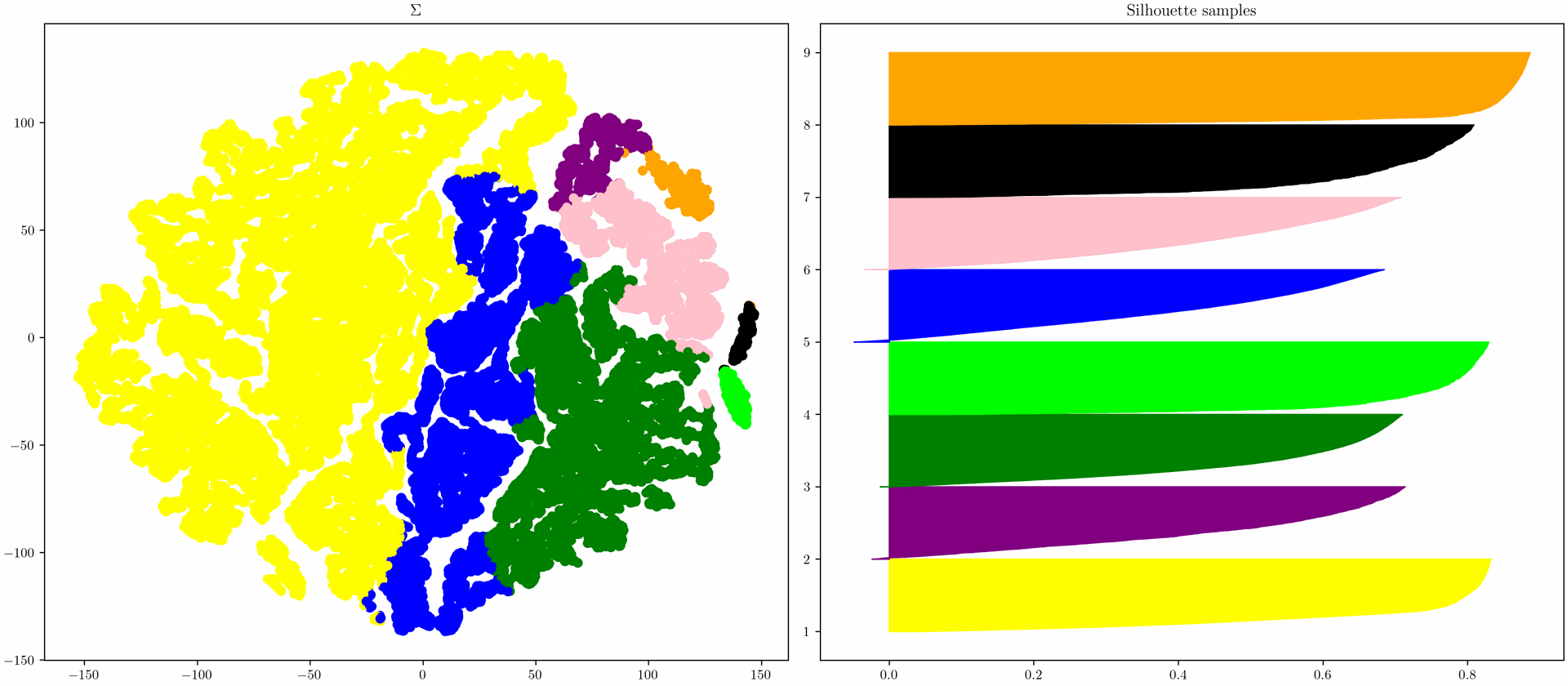
Links im Bild sieht man ein berechnetes Clustering auf Basis einer Komponente der SVD. Die Farben entsprechen den einzelnen Clustern.
Rechts im Bild sind die sogenannten "Silhouette Scores" für jeden einzelnen Prozessausschnitt des Clusterings dargestellt, der beschreibt wie gut die Cluster voneinander abgegrenzt sind. Silhouette Scores größer als Null zeigen an, dass das jeweilige Element gut in den eigenen Cluster integriert ist. Scores kleiner als Null zeigen dagegen an, dass die Zuordnung des Elements nicht optimal war und das es besser wäre es in ein anderes Cluster einzuordnen.
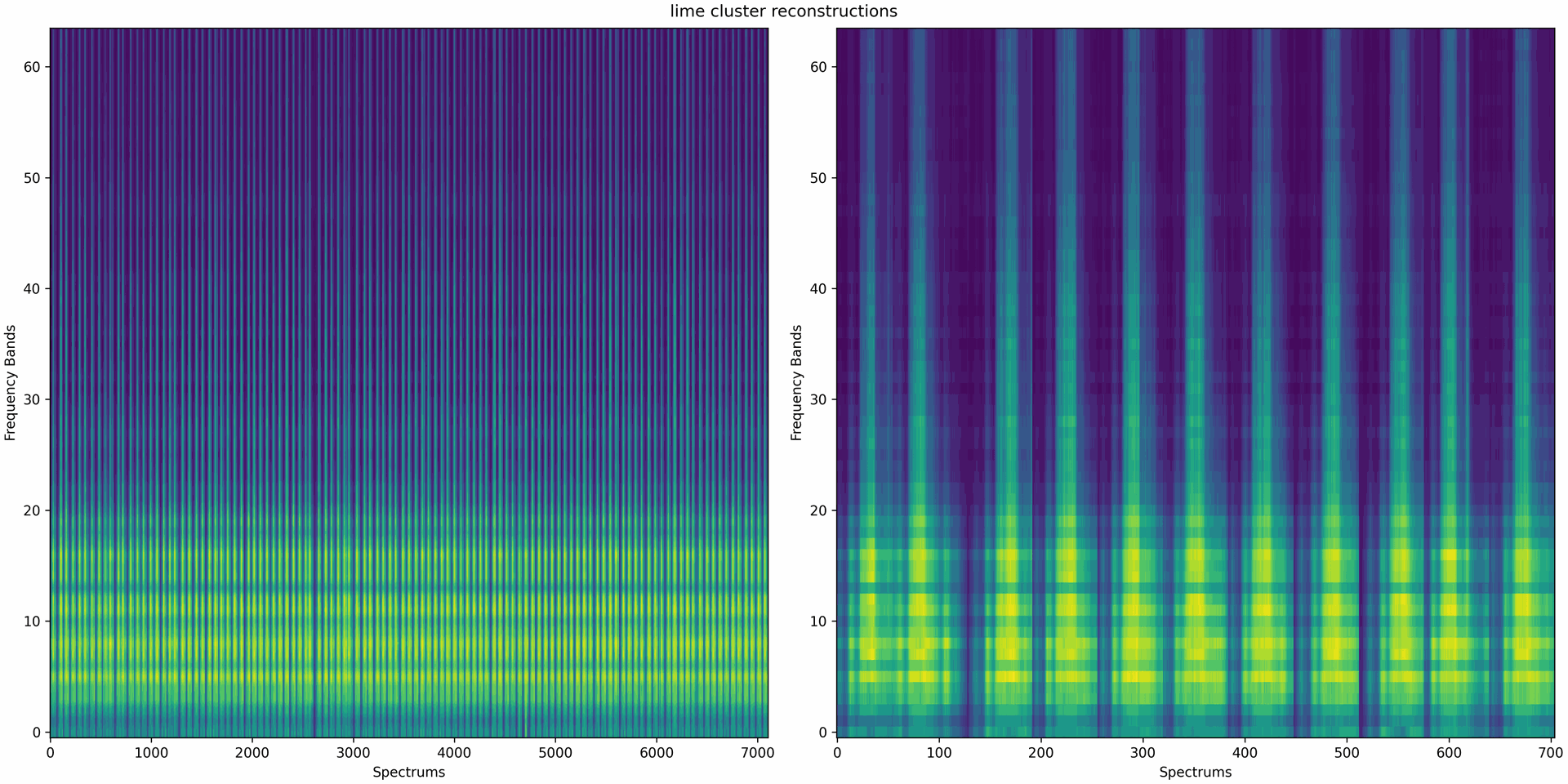
Das linke Bild zeigt 100 zufällige Prozessabschnitte aus dem hellgrünem Cluster. Das rechte Bild zeigt einen Ausschnitt des linken Bilds mit 10 Prozessabschnitten. Das homogene Erscheinungsbild der zufällig ausgewählten Prozessabschnitte zeigt, dass das Clustering der SVD Komponenten erfolgreich ähnliche Prozessabschnitte zusammenfasst.
Die Eigenschaft der Dimensionsreduktion der SVD kann ebenfalls zur Datenkompression verwendet werden.
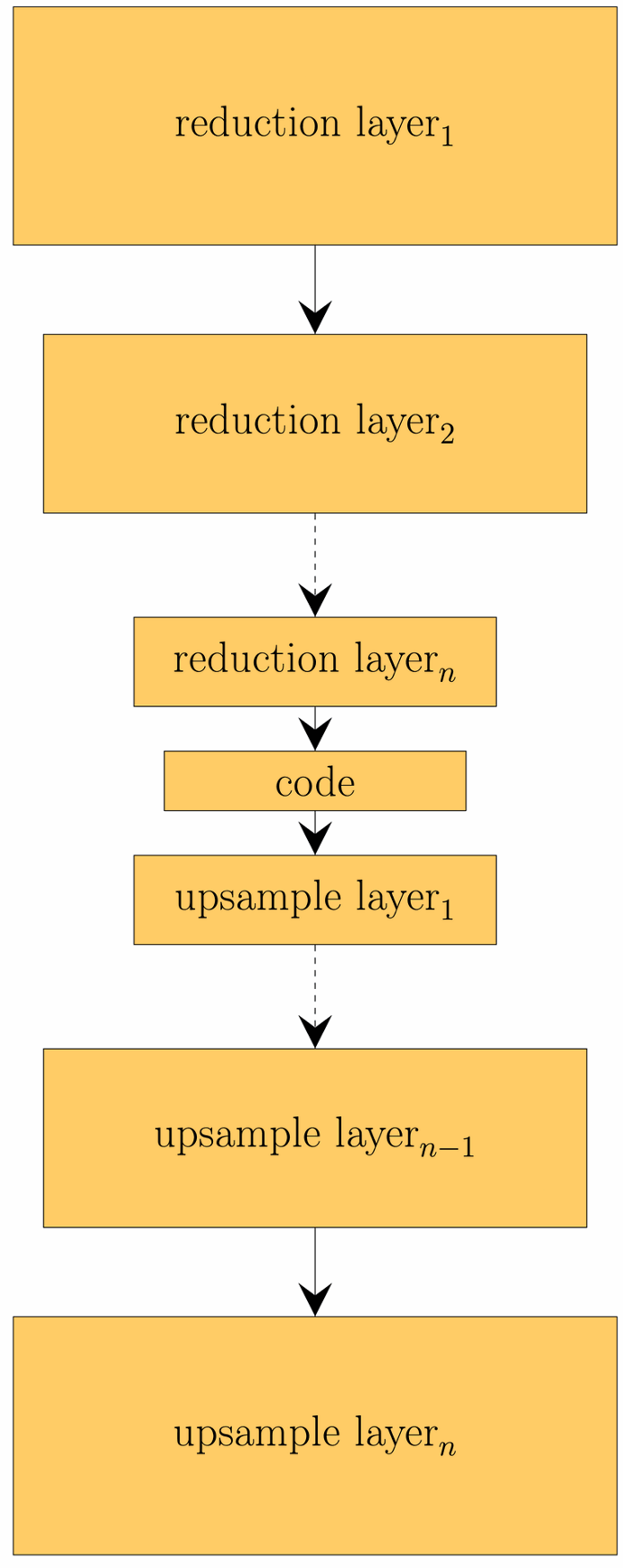
Dimensionsreduktion über Autoencoder
Alternativ zur oben betrachteten SVD, kann die Dimensionalität der Daten auch über einen sogenannten Autoencoder reduziert werden. Ein Autoencoder ist eine spezielle Form von neuronalem Netz, dass sich aus zwei Teilen zusammensetzt: einem Encoder und einem Decoder. Der Encoder reduziert die Dimensionalität der Eingangsdaten und bildet diese dabei auf einen Code ab, der die Daten repräsentiert. Über den Decoder können aus einem Code wieder die Eingangsdaten rekonstruiert werden. Diese Rekonstruktion ist in aller Regel fehlerbehaftet. Die Idee hinter dem gelernten Code ist, dass dieser komplexe Zusammenhänge der Eingabedaten repräsentiert. Dies ist ein Vorteil gegenüber SVD, die lediglich lineare Zusammenhänge darstellen kann.
Wie die SVD können Autoencoder auch zur Datenkompression genutzt werden.
Aufteilen von Prozessen in Signalabschnitte mit RBF Kernel
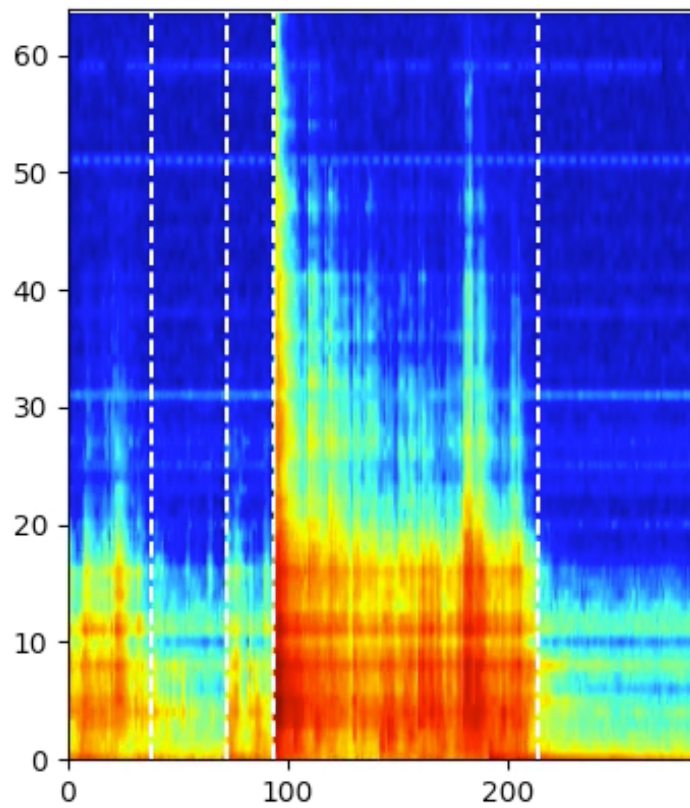
Eine Prozess lässt sich für gewöhnlich in mehrere Arbeitsschritte unterteilen, die man je nach Anwendung gesondert betrachten möchte. Sollte eine solche Aufteilung sich nicht bereits durch die Maschinenkommunikation ergeben oder noch noch fein genug sein, bedarf es einer Technik den Prozess einzig und allein anhand der Messsignals zu unterteilen.
Da unsere Daten in der Regel über mehrere Frequenzbänder verfügen, ist es von hoher Bedeutung, dazu zu betrachten, wie sich die Frequenzbänder untereinander verhalten.
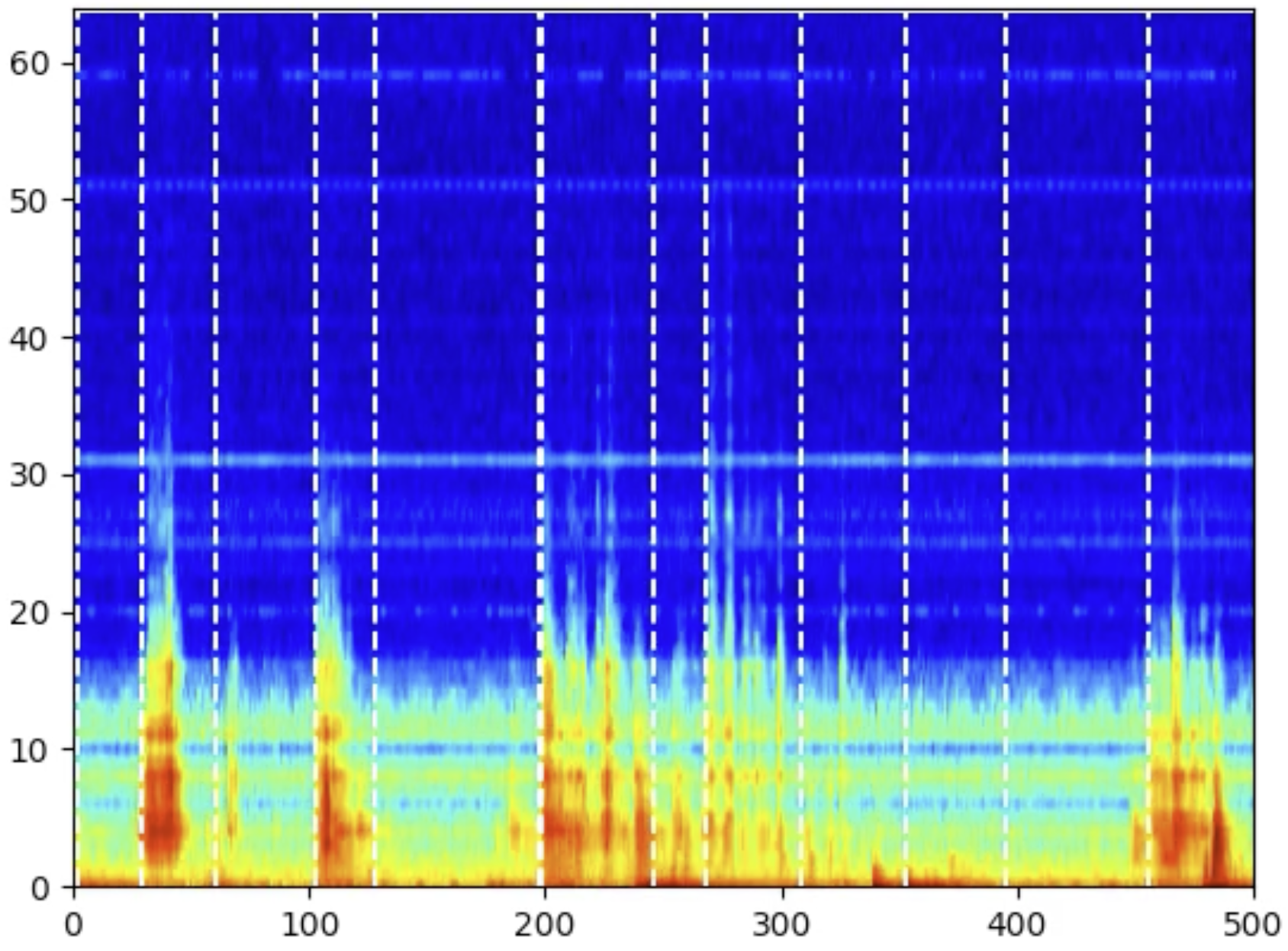
Problematisch ist dabei, dass es theoretisch unendlich viele Kombinationen geben kann, wie man die Frequenzbänder betrachtet. Eine mathematisch elegante und zugleich weitverbreitete Technik, um all diese Kombinationen kompakt darzustellen ist die Verwendung des Radial Basis Function Kernels (RBF Kernel). Dieser ermöglicht die Betrachtung aller Kombinationen ohne diese tatsächlich berechnen zu müssen. Der Kernel kann als Distanzmaß in einem transformierten Datenraum verstanden werden, der die Informationen aller Dimensionen der Daten kodiert. Verwendet man dann den RBF Kernel, um zu bestimmen, wie ähnlich sich aufeinanderfolgende Spektren sind, können wir die Zeitpunkte im Signal identifizieren, an denen sich die Signalcharakteristik ändert und somit ein neuer Signalabschnitt beginnt. In den beiden Abbildungen sehen wir jeweils einen Prozessausschnitt inklusive der Punkte an denen das Signal aufgeteilt wird, gekennzeichnet durch die weißen Linien.